
はじめに
ChatGPT のような対話AIが自然で安全な応答を返せる背景には、RLHF という仕組みがあります。
RLHFは「人間のフィードバックに基づく強化学習(Reinforcement Learning from Human Feedback)」の略で、AIの出力を人間が好む方向へ調整する方法です。
RLHFの基本ステップ
RLHFは大きく3段階に分けられます。
- 教師あり微調整(SFT)
人間が用意した模範データでベースモデルを微調整。 - 報酬モデルの学習(Reward Model)
複数候補の応答を人間が比較し、「どちらが良いか」をラベル付け。
→ それを学習して、応答の良し悪しをスコア化する関数 Rφ(x,y) を得る。 - 強化学習(PPOによる最適化)
報酬モデルを環境として扱い、ポリシー(モデル)を更新。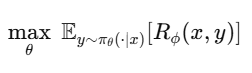 実際には PPO(Proximal Policy Optimization)を使い、学習が暴走しないように制御します。
実際には PPO(Proximal Policy Optimization)を使い、学習が暴走しないように制御します。
数式で見るRLHF

メリットと課題
- ✅ メリット
- 人間が好む応答を学習できる
- 安全性・有用性を高めやすい
- ChatGPTやInstructGPTで効果実証済み
- ⚠️ 課題
- 人間による評価データ収集にコストがかかる
- 報酬設計が難しい(誤学習のリスク)
- 一部で「幻覚(事実誤り)」が悪化する可能性も
まとめ
RLHFは、大規模言語モデルを 人間の価値観に沿って調整するための強力な手法 です。
ChatGPTの自然さや安全性の多くは、この仕組みによって実現されています。
今後は、効率的なフィードバック収集や、自動評価と組み合わせたRLHFの進化が重要なテーマとなるでしょう。

コメント