
- Palantirが言う「組織のデジタルツイン」の本質
- 1. はじめに
- 2. 一般的なオントロジーの意味
- 3. データベースとの違い
- 4. BIツールとの違い
- 5. PalantirのOntologyとは何か
- 6. Objects、Properties、Linksとは何か
- 7. Actionsとは何か
- 8. Functions、Models、AIとの関係
- 9. Dynamic Securityとは何か
- 10. なぜPalantirは「組織のデジタルツイン」と呼ぶのか
- 11. 単なるデータ統合ではない
- 12. タービン設計で考えるOntologyの例
- 13. AIエージェントとの相性
- 14. Palantir Ontologyの本質
- 15. 何がすごいのか
- 16. 注意点:万能ではない
- 17. 自社で考えるならどう始めるべきか
- 18. まとめ
Palantirが言う「組織のデジタルツイン」の本質
1. はじめに
最近、Palantirの説明の中でよく出てくる言葉にOntology、オントロジーがあります。
Palantirは、このOntologyを単なるデータベースではなく、組織のデジタルツインだと説明しています。
しかし、初めて聞くと少しわかりにくい言葉です。
「オントロジーとは何か?」
「データベースと何が違うのか?」
「なぜPalantirはそれを組織のデジタルツインと呼ぶのか?」
「AI時代に、なぜこれが重要なのか?」
この記事では、これらをできるだけわかりやすく整理します。
結論から言うと、オントロジーとは、
現実世界のモノ、人、業務、判断、権限を、コンピュータが理解して操作できる形に整理した“意味付きの業務地図”
です。
Palantirの場合、このオントロジーはさらに進んで、
会社の現実をデジタル上に再現し、人間とAIが同じ意味で理解し、判断し、アクションできる仕組み
になっています。
これが、Palantirが言う組織のデジタルツインです。
2. 一般的なオントロジーの意味
まず、一般的な意味でのオントロジーを説明します。
オントロジーとは、もともとは哲学の言葉で、「存在とは何か」を考える分野です。
しかし、ITやAIの世界では少し意味が変わります。
ITにおけるオントロジーとは、
ある世界に存在する概念と、それらの関係を定義したモデル
です。
例えば、会社の中には次のようなものがあります。
- 顧客
- 製品
- 工場
- 注文
- 在庫
- 設備
- 作業指示
- 担当者
- 承認者
- 売上
- トラブル
- 改善案
これらは単独で存在しているわけではありません。
顧客は製品を注文します。
製品は工場で作られます。
工場には設備があります。
設備には稼働状況があります。
在庫が不足すると納期に影響します。
納期が遅れると顧客に影響します。
誰かが判断し、誰かが承認し、誰かが対応します。
つまり、現実の業務は、単なるデータの集まりではなく、意味を持った関係のネットワークです。
この意味のネットワークを整理したものがオントロジーです。
3. データベースとの違い
オントロジーを理解するには、データベースとの違いを考えるとわかりやすいです。
普通のデータベースでは、情報はテーブルとして保存されます。
例えば、
- 顧客テーブル
- 製品テーブル
- 注文テーブル
- 在庫テーブル
- 設備テーブル
- 売上テーブル
のように分かれています。
これはとても重要です。
データを正確に保存するには、データベースは必要です。
しかし、データベースだけでは、現実の業務の意味までは十分に表現できません。
例えば、データベースには、
「注文番号12345の納期が遅れている」
というデータは入っているかもしれません。
しかし、それだけでは次のことはすぐにはわかりません。
- なぜ遅れているのか
- どの部品が不足しているのか
- どの工場に問題があるのか
- どの設備の停止が影響しているのか
- どの顧客に影響するのか
- 代替案はあるのか
- 誰が判断すべきなのか
- 誰が承認できるのか
- どのシステムを更新すべきなのか
オントロジーは、このような情報を現実の業務の意味に沿ってつなぐための仕組みです。
データベースが「データを保存する箱」だとすると、
オントロジーは「データを現実世界の意味に変換する地図」です。
4. BIツールとの違い
BI、つまりBusiness Intelligenceツールは、データを集計し、グラフやダッシュボードで見せるためのツールです。
BIは、
- 売上を見る
- 在庫を見る
- 稼働率を見る
- KPIを見る
- 異常値を見る
といった用途に強いです。
つまりBIは、基本的には、
今どうなっているかを見るための仕組み
です。
一方で、PalantirのOntologyは、それだけではありません。
PalantirのOntologyは、
- 現在の状態を見る
- 原因をたどる
- 関係を理解する
- 予測する
- 判断する
- アクションする
- 結果を業務システムに反映する
ところまで狙っています。
ここが重要です。
BIは「見る」ことが中心です。
Ontologyは「理解して、判断して、動かす」ことまで含みます。
この意味で、PalantirのOntologyは単なる分析基盤ではなく、業務を動かすための基盤に近いです。
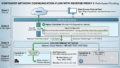
5. PalantirのOntologyとは何か
PalantirにおけるOntologyは、一般的な知識モデルよりもさらに実務的です。
PalantirのOntologyでは、組織のデータやモデルを、現実世界の業務オブジェクトに結びつけます。
例えば、製造業なら、
- 工場
- ライン
- 設備
- 部品
- 製品
- 作業指示
- 在庫
- 顧客注文
- 出荷
- 品質問題
- 保全計画
などが、デジタル上のオブジェクトとして表現されます。
そして、それぞれのオブジェクトにはプロパティがあります。
例えば、設備オブジェクトなら、
- 設備ID
- 設備名
- 設置場所
- 稼働状態
- 温度
- 圧力
- 保全履歴
- 故障リスク
- 担当部署
などがプロパティになります。
さらに、オブジェクト同士にはリンクがあります。
例えば、
- 設備は工場に属する
- 工場は製品を生産する
- 製品は顧客注文に対応する
- 部品は製品に使われる
- 作業指示は設備に関連する
- 故障は保全計画に関連する
という関係です。
つまり、PalantirのOntologyは、
現実の業務を、オブジェクト、プロパティ、リンクとしてデジタル上に再構成する仕組み
です。
6. Objects、Properties、Linksとは何か
PalantirのOntologyを理解するうえで、特に重要なのが次の3つです。
6.1 Object
Objectとは、現実世界に存在する「もの」や「概念」です。
例えば、
- 顧客
- 工場
- 設備
- 製品
- 部品
- 注文
- 出荷
- 作業指示
- CFD計算ケース
- 試験結果
- 設計案
などです。
Objectは、単なるデータ行ではありません。
現実世界の意味を持つ単位です。
例えば「設備A」というObjectがあれば、それは単なるIDではなく、実際の工場にある設備Aを表します。
6.2 Property
Propertyとは、Objectが持つ属性です。
例えば、設備Objectなら、
- 設備名
- 場所
- 状態
- 稼働率
- 温度
- 圧力
- メンテナンス予定日
などがPropertyです。
タービン設計で考えると、BladeというObjectには、
- 翼高さ
- コード長
- 入口角
- 出口角
- 反動度
- マッハ数
- 損失係数
などのPropertyを持たせることができます。
6.3 Link
Linkとは、Object同士の関係です。
例えば、
- 顧客注文は製品に関係する
- 製品は部品を使う
- 部品はサプライヤーから供給される
- 設備は工場に設置されている
- 作業指示は設備に対して発行される
- CFD計算ケースは設計案に紐づく
- 試験結果は特定のタービン仕様に紐づく
という関係です。
このLinkがあることで、単なる表形式のデータではなく、業務全体をネットワークとして理解できるようになります。
7. Actionsとは何か
PalantirのOntologyで非常に重要なのが、Actionsです。
Actionsとは、簡単に言うと、
Ontology上のObjectやPropertyやLinkを変更するための業務アクション
です。
例えば、
- 在庫を更新する
- 作業指示を発行する
- 設備の状態を変更する
- 発注を承認する
- 納期を変更する
- 設計案を承認する
- CFD計算を実行する
- 保全計画を登録する
といった操作です。
ここが、普通のデータモデルとの大きな違いです。
普通のデータモデルは、情報を表現するだけです。
しかしPalantirのOntologyは、情報を表現するだけでなく、業務上の操作も定義することができます。
つまり、PalantirのOntologyは「見るためのモデル」ではなく、「業務を動かすためのモデル」です。
8. Functions、Models、AIとの関係
PalantirのOntologyは、データだけでなく、モデルや関数とも接続できます。
例えば、
- 需要予測モデル
- 故障予測モデル
- 最適化モデル
- スケジューリングモデル
- コスト推定モデル
- CFD計算モデル
- 品質予測モデル
- LLMエージェント
などです。
これらをOntology上のObjectに接続すると、AIや数理モデルが、現実の業務オブジェクトを直接扱えるようになります。
例えば、AIが単に、
「在庫が不足しています」
と答えるだけでなく、
「この部品の不足により、製品Aの出荷が3日遅れる可能性があります。代替サプライヤーBを使うと、コストは上がりますが納期遅延は回避できます。承認しますか?」
という判断支援ができるようになります。
さらに、必要であればActionを通じて、
- 発注変更
- スケジュール変更
- 担当者通知
- 承認依頼
- システム更新
まで実行できます。
これが、AI時代にOntologyが重要になる理由です。
9. Dynamic Securityとは何か
PalantirのOntologyでは、権限管理も重要です。
現実の組織では、すべての人がすべてのデータを見たり変更したりできるわけではありません。
例えば、
- 現場担当者は設備状態を更新できる
- 管理者は作業指示を承認できる
- 経営層は全体KPIを見られる
- 外部委託先は一部の情報だけ見られる
- AIエージェントは許可されたActionだけ実行できる
というような制御が必要です。
PalantirのOntologyでは、Object、Link、Actionなどに対して細かく権限を設定できます。
これは、AI活用において非常に重要です。
なぜなら、AIに業務を任せる場合、
「AIが何を見てよいか」
「AIが何を変更してよいか」
「AIがどこまで自律的に判断してよいか」
を厳密に管理する必要があるからです。
Ontologyは、人間とAIが同じ業務空間で働くための、安全な土台になります。
10. なぜPalantirは「組織のデジタルツイン」と呼ぶのか
一般的にデジタルツインというと、工場設備や航空機エンジンなどの物理システムをデジタル上に再現するものを想像します。
例えば、
- 発電プラントのデジタルツイン
- 工場ラインのデジタルツイン
- 航空機エンジンのデジタルツイン
- タービンのデジタルツイン
などです。
これらは、物理的な対象をデジタル上に再現し、状態監視、シミュレーション、予測、最適化に使います。
Palantirが言う「組織のデジタルツイン」は、これを会社全体に広げた考え方です。
つまり、対象は設備だけではありません。
- 人
- 部署
- 工場
- 顧客
- サプライヤー
- 製品
- 注文
- 在庫
- 作業
- 判断
- 承認
- ワークフロー
- AIモデル
- 業務アプリ
まで含めて、組織全体をデジタル上に表現します。
そのため、PalantirのOntologyは、
会社の現実世界をデジタル上に写した業務モデル
と考えることができます。
11. 単なるデータ統合ではない
多くの企業では、すでに大量のデータがあります。
しかし、そのデータはバラバラです。
例えば、
- ERP
- MES
- PLM
- CRM
- Excel
- SharePoint
- センサーデータ
- 品質データ
- 設計データ
- 試験データ
- 文書データ
などが、それぞれ別々に存在しています。
データ統合というと、これらを一か所に集めることを想像しがちです。
しかし、ただ集めるだけでは不十分です。
重要なのは、
それぞれのデータが、現実のどの業務オブジェクトに対応しているのかを明確にすること
です。
例えば、あるExcelファイルに「Case_001」という名前の計算結果があるとします。
それだけでは意味が不明です。
しかしOntology上で、
- Case_001はCFD計算ケースである
- この計算ケースはタービン設計案Aに紐づいている
- 設計案Aは顧客仕様Xに対応している
- 顧客仕様Xでは効率とコストが重要である
- この計算ケースの結果では出口損失が高い
- そのため設計変更候補Bが提案されている
という関係が定義されていれば、データは業務判断に使える情報になります。
これがOntologyの価値です。
12. タービン設計で考えるOntologyの例
タービン設計業務で考えると、Ontologyは非常に相性が良いです。
例えば、以下のようなObjectを定義できます。
- Turbine
- Stage
- Blade
- Nozzle
- Rotor
- Casing
- Customer Requirement
- Design Case
- CFD Case
- Test Result
- Performance Map
- Loss Model
- Cost Estimate
- Manufacturing Constraint
- Design Review
- Approval Request
それぞれにPropertyを持たせます。
例えば、Stageなら、
- 段番号
- 入口圧力
- 出口圧力
- 入口温度
- 出口温度
- 反動度
- 流量
- 段効率
- マッハ数
- 湿り度
- 損失係数
などです。
Bladeなら、
- コード長
- 翼高さ
- 入口角
- 出口角
- 厚み分布
- 前縁半径
- 後縁厚み
- 製造制約
- 強度制約
- 固有振動数
などです。
さらにLinkとして、
- Turbineは複数のStageを持つ
- StageはNozzleとBladeを持つ
- BladeはDesign Caseに属する
- Design CaseはCFD Caseを持つ
- CFD CaseはPerformance Mapを出力する
- Performance MapはCustomer Requirementと比較される
- Test ResultはDesign Caseを検証する
- Design ReviewはDesign Caseを承認または差し戻す
といった関係を定義できます。
こうすると、タービン設計の膨大な情報が、単なるファイルや表ではなく、意味のある設計ネットワークになります。
13. AIエージェントとの相性
Ontologyは、AIエージェントと非常に相性が良いです。
なぜなら、AIエージェントは単に文章を読むだけでは、業務の正しい意味や権限を完全には理解できないからです。
例えば、AIに対して、
「このタービン設計を改善して」
と指示しても、AIだけでは次のことが曖昧です。
- どの設計案を対象にするのか
- 評価指標は効率なのか、コストなのか、信頼性なのか
- どの制約条件を守るべきか
- どのCFD結果を参照すべきか
- どの設計変更が許可されているのか
- 誰の承認が必要なのか
- 変更後にどのシステムを更新すべきか
Ontologyがあれば、AIはこれらをObject、Property、Link、Actionとして扱えます。
つまり、AIが業務の文脈を理解しやすくなります。
さらに、AIができることとできないことをActionとして制御できます。
例えば、
- AIは設計候補を提案できる
- AIはCFD計算を起動できる
- AIは結果を要約できる
- AIはレビュー依頼を作成できる
- しかしAIは最終承認はできない
というように管理できます。
これにより、AIは単なるチャットボットではなく、業務を支援する実行エージェントに近づきます。
14. Palantir Ontologyの本質
PalantirのOntologyの本質は、次の3つに整理できます。
14.1 Semantic Layer
まず、Semantic Layerです。
これは、データに意味を与える層です。
単なるテーブル名やカラム名ではなく、
- これは顧客である
- これは設備である
- これは注文である
- これは設計案である
- これはCFD結果である
というように、業務上の意味を与えます。
14.2 Kinetic Layer
次に、Kinetic Layerです。
Kineticとは「動き」に関係する言葉です。
PalantirのOntologyでは、Actionを通じて、業務上の変更や操作を表現できます。
つまり、Ontologyは静的なデータモデルではなく、業務を動かすモデルです。
14.3 Operational Layer
最後に、Operational Layerです。
Ontologyは、分析だけでなく、実際の業務運用に接続されます。
現場の人、管理者、経営者、AIエージェントが、同じOntologyを通じて業務を理解し、判断し、行動します。
この意味で、Ontologyは組織の共通言語であり、業務OSのような役割を持ちます。
15. 何がすごいのか
PalantirのOntologyがすごいのは、データ、モデル、アプリ、AI、業務アクションを一つの意味空間にまとめようとしている点です。
従来の企業システムでは、
- データはデータ基盤にある
- モデルはデータサイエンス環境にある
- アプリは別に作る
- 権限は別システムで管理する
- 業務判断はExcelや会議で行う
- AIはチャットツールとして使う
というように、バラバラになりがちです。
PalantirのOntologyは、これらを統合し、
人間とAIが同じ業務モデルを見ながら判断し、必要なアクションを実行する
ことを目指しています。
これは、企業にとって非常に大きな変化です。
16. 注意点:万能ではない
ただし、Ontologyは魔法ではありません。
作れば自動的に会社が賢くなるわけではありません。
重要なのは、現実の業務を正しく理解し、適切にObject、Property、Link、Actionに分解することです。
ここを間違えると、使いにくいOntologyになります。
また、全社の業務を一気に完全にモデル化しようとすると失敗しやすいです。
最初は、重要なユースケースに絞るべきです。
例えば、
- 在庫不足の予測
- 設備保全
- 納期遅延リスク
- 設計変更管理
- CFD計算ケース管理
- 顧客仕様と設計案の紐づけ
- 試験結果と設計モデルの比較
のように、具体的な業務課題から始めるのが現実的です。
Ontologyは一度に完成させるものではなく、業務の中で育てていくものです。
17. 自社で考えるならどう始めるべきか
Palantirのような大規模プラットフォームをすぐに導入しなくても、Ontology的な考え方は自社の業務整理に使えます。
まずは、次のように考えるとよいです。
Step 1:重要な業務対象を洗い出す
例えば、タービン設計なら、
- 顧客仕様
- タービン
- 段
- 翼
- 設計案
- CFDケース
- 試験結果
- 損失モデル
- コスト
- レビュー
を洗い出します。
Step 2:それぞれの属性を整理する
例えば、CFDケースなら、
- ケース名
- 対象設計
- 境界条件
- メッシュ条件
- 解析条件
- 収束状況
- 出力結果
- 担当者
- 実行日
を整理します。
Step 3:関係性を整理する
例えば、
- 設計案は複数のCFDケースを持つ
- CFDケースは特定の境界条件を使う
- 試験結果は設計案を検証する
- 顧客仕様は設計評価基準を決める
- レビューは設計案を承認する
という関係です。
Step 4:業務アクションを整理する
例えば、
- CFDを実行する
- 設計案を登録する
- 結果をレビューする
- 差し戻す
- 承認する
- 顧客仕様と照合する
- コストを再計算する
といったActionを定義します。
Step 5:AIに任せる範囲を決める
最後に、AIができることを決めます。
例えば、
- AIは候補設計を提案する
- AIは過去ケースを検索する
- AIはCFD結果を要約する
- AIは設計レビュー用の資料を作る
- AIは承認はしない
というように、人間とAIの役割分担を決めます。
この考え方が、Ontologyを実務に使う第一歩です。
18. まとめ
オントロジーとは、単なるデータ構造ではありません。
それは、
現実世界のモノ、人、業務、判断、権限を、意味付きで整理した業務モデル
です。
PalantirのOntologyは、さらにそれを発展させて、
組織全体をデジタル上に再現し、人間とAIが同じ意味で理解し、判断し、アクションできる基盤
にしています。
だからPalantirは、Ontologyを組織のデジタルツインと呼んでいます。
重要なのは、Ontologyが単なるデータベースではないことです。
データベースはデータを保存します。
BIはデータを見せます。
Ontologyはデータに意味を与え、業務の関係を表し、アクションにつなげます。
AI時代には、単にデータを持っているだけでは不十分です。
AIが正しく判断するためには、データの意味、関係、権限、アクションが整理されている必要があります。
その土台になるのがOntologyです。
特に、設計、製造、保全、物流、エネルギー、防衛、金融のように、複雑な業務判断が多い分野では、Ontologyの重要性はますます高まるでしょう。
一言でまとめるなら、こうです。
Ontologyとは、会社の現実をAIと人間が一緒に扱えるようにするための、意味付きの業務地図である。
そしてPalantirのOntologyとは、
その業務地図を、実際に判断し、操作し、業務を動かすためのデジタルツインにしたもの
だと言えます。

コメント