製造業の設計領域でいう「ナレッジAI」は、もう単なる社内文書検索ではありません。2026年時点の主戦場は、文書コーパスを読むRAGから、権威データをつなぐデジタルスレッド、文書から抽出した知識グラフ、手順を再利用するSkillBank、そしてCAEを高速化するAIサロゲートを統合した多層メモリ型アーキテクチャへ移っています。GraphRAGは知識グラフとコミュニティ要約を軸に多段の推論を支え、RAPTORは文書全体を要約木として扱い、Anything2SkillやCorpus2Skillは「情報アクセス」から「実行可能な手順再利用」へ軸足を移し、MCPとAgent Skillsはその実行面を標準化しつつあります。製造業側でも、SysML v2、OSLC、STEP AP242、PLMネイティブAI、Simulation-AIがこの流れと合流し始めています。
本レポートでは、タービン設計システムを代表例にしつつ、一般の製造設計にもそのまま展開できる形で、考え方と実ツールを一気通貫で整理します。前提条件として、予算と既存ツールチェーンは未指定なので、設計はベンダーニュートラルに置き、必要なところだけ現実的なツール候補をはめる構成にします。なお、ここでいう「ナレッジ」は、文章・図面・PMI・BOM・要求・解析条件・不具合・判断理由・承認履歴・実行手順まで含む広い概念です。デジタルスレッドの考え方自体が、要求、製品情報、文書、品質、欠陥、保守などをライフサイクル全体で結ぶものとして整理されています。
エグゼクティブサマリー
いちばん重要な結論は、製造業設計のナレッジAIは「単層のRAG」を卒業し、「証拠メモリ」「構造メモリ」「手順メモリ」「物理メモリ」を重ねる方向に進んでいる、ということです。証拠メモリは文書やログ、構造メモリはSysML v2・PLM・AP242・知識グラフ、手順メモリはAnything2SkillやAgent Skillsのような再利用可能スキル、物理メモリはSimAIやPhysicsAIのようなシミュレーション由来のサロゲート群です。これらを分離しつつ参照統合する設計が、設計現場では最も安定します。
RAGがだめなのではなく、RAG「だけ」では足りない、というのが現在の実務感です。RAGは、関連文脈を取得できれば非常に有効ですが、検索失敗やノイズ混入でハルシネーションが起きやすく、長い文脈でも「真ん中に埋もれた重要情報」を取りこぼしやすいことが知られています。さらに製造設計では、部品番号・改訂版・適用範囲・承認状態・PMI・解析条件のような厳密一致と、因果・依存関係・変更波及のようなグラフ的推論が同時に必要になるため、ベクトル検索だけでは限界が出ます。
今すぐ現場で使える実ツールも、潮流をかなりはっきり反映しています。SiemensのTeamcenter Copilotは、Teamcenter管理データに基づく知識ベース、引用付き応答、BOM探索、ドキュメント理解、権限チェックを前提にしたPLMネイティブAIです。Dassault Systèmesは3DEXPERIENCE上でAura、Leo、MarieというVirtual Companionsを展開し、CATIAではAI-driven generative experiencesを打ち出しています。AnsysはSimAIとGeomAI、Altair系のPhysicsAIはCAEデータからの高速予測モデル群として、設計探索を大きく前倒ししています。
したがって、タービン設計向けの推奨解は、PLM/MBSE/CAEの権威ソースを中心に、文書由来のGraphRAG、厳密一致用のキーワード索引、意味検索用のベクトル索引、手順知識のSkillBank、そして高価値候補だけをソルバー再計算で検証する安全弁を組み合わせる構成です。言い換えると、「全部をLLMに覚えさせる」のではなく、「権威ソースとAI補助層を明確に役割分担させる」のが正解です。
進化の地図と時間軸
製造設計ナレッジAIの進化は、ばらばらに見えて実は一本の線でつながっています。前半は「設計データを標準化し、つなぐ」時代で、STEP AP242、RDF/OWL、SHACL、OSLC、そしてSysML v2 APIがここに属します。後半は「つながった知識をLLMがどう使うか」の時代で、RAG、RAPTOR、GraphRAG、Agentic RAG、MCP、Agent Skills、SkillBankがここに入ります。2025年以降はさらに、PLM/CAEベンダーが自前の権威データに生成AIを直接組み込む流れが加速しました。
2014STEP AP242 Edition 1公開2017SHACL 勧告で RDF検証が実務化2023SysML v2 / SystemsModeling APIベータ採択2024RAPTOR 論文GraphRAG 論文RAG vs Long Context比較が本格化Ansys SimAIが設計探索に浸透2025SysML v2 最終採択MCP 仕様が普及Teamcenter CopilotがPLM組込みAIとして前進STEP AP242 Edition 4公開Agent Skills 公開2026Corpus2Skill 論文Anything2Skill 論文Dassault VirtualCompanions 展開Ansys GeomAI /SimAI Pro 登場OWASP Agentic Top10 公開2027+SkillBank と DigitalThread の統合Solver-groundedAgent の定着認証可能な設計AIワークフローへ製造設計ナレッジAIの進化Show code
この年表で特に重いのは、三つの収束です。ひとつ目は、SysML v2 APIとOSLC、AP242が「設計の正本」を機械可読にし始めたことです。ふたつ目は、GraphRAGやRAPTORが「文書の理解」を、要約木やコミュニティ要約を使って、単純な top-k chunk 検索より一段深くしたことです。みっつ目は、Anything2Skill、Corpus2Skill、Agent Skillsが、暗黙の作業手順を再利用可能な実行単位へ変換し始めたことです。これで、検索AIは“答えるだけ”から“やり方を再現する”段階に入りました。
近未来のトレンドもわりとはっきりしています。今後は、GraphRAGのような抽出グラフ単独ではなく、PLM/MBSE/AP242から来る「権威グラフ」と文書由来の「推論補助グラフ」を重ねる実装が増えます。さらに、MCP/Skillsを経由して、AIが検索だけでなく設計レビュー、解析テンプレート生成、変更影響の洗い出し、報告書作成まで一連で扱うようになります。ただし、そのときの勝負はモデル性能よりも、権限・承認・版管理・評価設計になります。MCP仕様自体も、ツールは危険な任意コード実行面を持つため注意が必要で、明示的なユーザー同意を要求しています。
ナレッジの種類と表現
製造設計で扱うべきナレッジは、最低でも七種類に分けて考えたほうが実装がうまくいきます。理由は、Search/RAGに強い表現、グラフに強い表現、検証に強い表現、実行に強い表現が違うからです。RDF/OWLはデータ統合と推論、SHACLは検証、SysML v2はシステム構造と要求、AP242は機械設計とPMIと分析管理、OSLCは横断リンク、SkillBankは手順再利用に向いています。つまり、ナレッジを一つの“巨大ベクトルDB”に押し込むより、型に応じた置き場を分けるべきです。
下表は、タービン設計を想定した実装向けのナレッジ類型です。これはSysML v2、AP242、OSLC、RDF/OWL/SHACL、SkillBank系研究を重ねて作った実務的な分類例で、特定ベンダーに依存しません。
| ナレッジ種別 | 典型例 | 代表的な表現形式 | 主な保存先 | 取り出し方の勘所 |
|---|---|---|---|---|
| 意図・要求ナレッジ | 最高温度条件、寿命要求、騒音制約、認証条件 | SysML v2、要件DB、RDF triples、表形式 | ALM / MBSE / グラフ | 要求ID・適用範囲・検証状態の厳密一致 |
| 構造・構成ナレッジ | システム分解、BOM、翼・ディスク・ケース関係 | SysML v2、PLM構造、OSLCリンク、RDF/Property Graph | PLM / グラフ | 親子・割当・依存関係のグラフ探索 |
| 形状・PMIナレッジ | CAD形状、寸法、公差、注記、断面、面状態 | STEP AP242、CAD原本、JT/派生ビュー | CAD / PLM / AP242庫 | 部品番号、面・特徴、PMIアンカーの正確追跡 |
| 解析・物理ナレッジ | CFD/FEA条件、境界条件、メッシュ、結果、妥当化 | CAE DB、AP242 analysis management、HDF5/CSV/JSON | CAE / PLM / グラフ | ケース条件、設計変数、仮定の追跡 |
| ルール・制約ナレッジ | 設計規準、社内標準、禁則、材料選定ルール | 文章、表、決定表、SHACL/ルール | 文書庫 / ルール層 / グラフ | exact match と symbolic filter の併用 |
| 製造・工程ナレッジ | 加工可能性、治具、工程順、品質ゲート、逸脱条件 | MES/ERP/工程票/AP242 process plan | ERP / MES / PLM / グラフ | 版・工程・製番・ロットの結び付け |
| 現場・品質ナレッジ | NCR、不具合報告、検査結果、フィールド故障 | QMS/Ticket/ログ/画像/表 | QMS / Data Lake / グラフ | 部番・シリアル・変更とのトレース |
| 判断・根拠ナレッジ | なぜその翼端クリアランスにしたか、なぜその材料変更を承認したか | DRBFM、会議議事録、ADR、レビュー記録 | 文書庫 / グラフ | 決定・根拠・影響範囲の関係抽出 |
| 手順・実行ナレッジ | 解析立上げ手順、レビュー手順、変更影響チェックリスト | SKILL.md、YAML/JSON skill contract、スクリプト | SkillBank / Git / Agent Layer | 再利用可能な procedural memory として扱う |
この分類をさらに抽象化すると、設計知識は「宣言的知識」「関係知識」「手続き知識」「検証知識」に分かれます。宣言的知識はRAGで取り出しやすいですが、関係知識はGraphRAGやデジタルスレッド、手続き知識はSkill化、検証知識はSHACLやソルバー再計算で担保するのが自然です。Anything2Skillが skill contract に invocation conditions、contraindications、workflow steps、constraints、supporting evidence を持たせているのは、まさに“文章を手順知識へ変換する”設計思想です。
RAGの限界と次世代手法
RAGがよく刺さるのは、「答えが文書のどこかにほぼそのまま書いてある」場合です。逆に製造設計で難しいのは、「複数文書・複数版・複数システムをまたいで、何が根拠で、どの変更が、どの部品・解析・不具合に波及したか」を追う場面です。そこでは chunk 単位の top-k 検索だけだと、文脈が細切れになり、階層構造と因果構造が失われます。RAPTORは既存法が短い連続チャンクしか取れず、文書全体の理解に限界があると指摘し、GraphRAGは一般的で全体的な質問に対して単純RAGでは弱いことを背景に提案されました。
TruLensのRAG Triadが示す通り、RAGでは少なくとも context relevance、groundedness、answer relevance を分けて見ないと、検索失敗と生成失敗が混ざります。さらに、長文コンテキストにすれば全部解決するわけでもなく、Lost in the Middle では、重要情報がコンテキスト中央にあると性能が落ちることが示されています。最近の比較研究でも、RAGとLong Context LLMは一長一短で、どちらか一方の勝ちではなくハイブリッド発想が必要という結論になっています。
製造業でRAGが破綻しやすい条件を、設計実務の観点でまとめると次の表になります。この表の右側が、そのまま次世代設計の方針です。前半の失敗モードは研究・評価の知見、後半の対処は本稿の設計提案です。
| 失敗モード | なぜ製造設計で深刻か | より良いパターン |
|---|---|---|
| チャンク分断 | 仕様・図面・解析条件・結論が別チャンクに割れる | RAPTOR型要約木、文書単位再構成 |
| 多段関係が弱い | part→revision→simulation→issue の経路が必要 | GraphRAG / 権威グラフ探索 |
| 厳密一致が弱い | 部番、要求ID、版、PMI、材料規格は曖昧一致が危険 | exact match + symbolic filter |
| 版管理に弱い | obsolete 文書や未承認版が混ざると事故になる | release state / effectivity で事前フィルタ |
| 手順再現が弱い | 解析立上げやレビュー手順は、文章片ではなく工程列 | SkillBank / Agent Skills |
| 長文詰め込みに過信 | 真ん中の重要条件を見落とす | context packing / evidence ranking |
| 根拠が曖昧 | なぜその答えになったか監査できない | citation + path trace + audit log |
| 画像・CAD・PMIの意味が落ちる | テキスト化だけでは幾何・公差の意味が抜ける | AP242/CAD anchor 参照型回答 |
GraphRAGの意味
GraphRAGの重要点は、「文書をベクトル化して似ている断片を返す」から、「文書からエンティティと関係を抽出してグラフ化し、そのグラフを階層クラスタ化してコミュニティ要約を作る」へ進めたことです。Microsoftの説明では、GraphRAGは知識グラフ、コミュニティ要約、グラフ機械学習の出力を query time のプロンプト増強に使います。さらに、Global Search はコーパス全体の俯瞰質問、Local Search は特定エンティティ周辺、DRIFT Search は局所探索にコミュニティ文脈を加える形に整理されています。製造設計で言えば、Global は「最近の温度余裕低下の全体傾向」、Local は「この翼改訂版の変更影響」、DRIFT は「この翼の変更がどの不具合群と設計判断に接続しているか」に対応します。
ただし、製造業でそのまま GraphRAG を入れると弱点もあります。GraphRAGは主にテキストから抽出したグラフを前提にしますが、設計現場には、すでにPLM、MBSE、AP242、QMSに権威的な関係が存在しています。だから実務では、「GraphRAGで抽出した推論補助グラフ」を、「PLM/MBSE/AP242/OSLC由来の権威グラフ」の上にオーバーレイするのがよく、抽出グラフが正本を置き換えるべきではありません。
Agentic RAGの意味
Agentic RAGは、検索を一発で終わらせず、反省、計画、ツール利用、場合によっては複数エージェント協調を使って、検索戦略を動的に変える考え方です。Survey では、reflection、planning、tool use、multi-agent collaboration が主要パターンとして整理されています。設計業務へ当てはめると、「まず要求と部番の exact lookup を優先し、次にグラフで影響先をたどり、最後に必要なら解析テンプレート作成ツールやPMIビューアを叩く」といった順序設計になります。Agentic RAGの価値は、検索の精度それ自体よりも、問いの種類ごとに retrieval plan を切り替えられる点にあります。
RAPTORと階層検索の意味
RAPTORは、テキスト断片を再帰的に埋め込み、クラスタリングし、要約して木構造を作ります。平たく言うと、「ページ断片を読む」検索から「文書全体を段階的に俯瞰してから下へ降りる」検索に変える技術です。設計標準、レビュー報告書、試験報告書のように、全体の論理構造が重要な文書には特に相性がよく、GraphRAGほど重いエンティティ抽出をしなくても、単純RAGより“全文脈”を扱いやすくなります。製造業の第一段階では、GraphRAGより先にRAPTOR型の階層要約を入れるほうが費用対効果が高いケースも多いです。
Corpus2SkillとAnything2Skillの意味
ここが、いま一番“新しい”ところです。Corpus2Skillは、文書コーパスをコンパイル時に階層スキルへ変換し、実行時にはLLMがその階層をたどって必要文書へ降りていく方式です。公式実装では、serve time にベクトルDBや retrieval index を持たず、SKILL.md / INDEX.md を読んで階層をナビゲートし、必要な文書IDだけ get_document で取りにいく設計が示されています。Anything2Skillはさらに一歩進んで、文書・マニュアル・対話・ログ・軌跡から、invocation conditions、contraindications、action moves、workflow steps、constraints、output specifications、supporting evidence、confidence scores を持つ structured skill contracts を生成し、versioned SkillBank に格納します。これは、設計ナレッジを「答えの根拠」から「再利用可能な作業単位」へ変える発想です。
製造設計にこれを入れると、効果が大きいのは、頻出だけど属人化しやすい業務です。たとえば「翼先端温度超過時の一次切り分け」「公差逸脱時の関連PMI・工程・不具合の引き当て」「解析条件変更のレビュー観点抽出」「標準部品代替可否の検討」などです。文章検索だけだと毎回ゼロから読解が必要ですが、SkillBankにしておけば、LLMは“作法”を再現しやすくなります。Anything2Skillのベンチマークが command-line tasks で強いのも、事実知識より手順知識の差が大きいからです。
MCPとAgent Skillsの意味
MCPは、AIアプリが外部システムとつながるためのオープン標準で、resources、prompts、tools をサーバー側機能として定義しています。ホスト、クライアント、サーバーの役割が分かれていて、JSON-RPC 2.0 を使い、ツール実行には明示的なユーザー同意を求め、ツール記述は信頼されていない入力として扱うべきだと仕様が明記しています。Agent Skillsはその上位概念というより、「エージェントが特定作業を上手に行うための手順パッケージ」で、Anthropicの実装では folder + SKILL.md が基本単位です。つまり、MCPは接続標準、Skillsは再利用可能な業務能力の包み方だと考えると整理しやすいです。
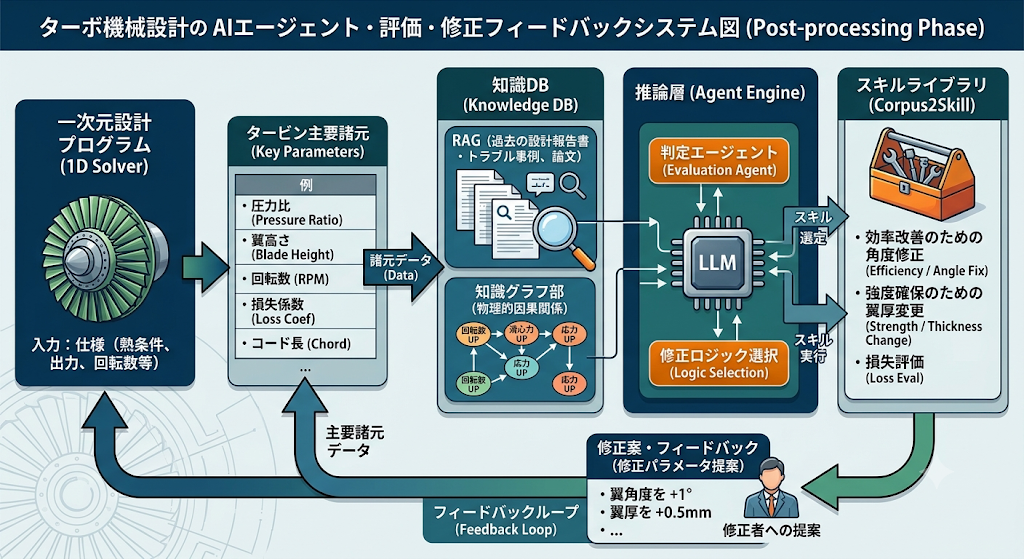
タービン設計向け推奨アーキテクチャ
タービン設計向けの最適解は、文書RAGを中心に組むのではなく、デジタルスレッドを中心に据え、その周囲に検索・グラフ・スキル・シミュレーションAIを層として重ねる構成です。AWSの製造デジタルスレッド指針でも、PLM・ERP・MESなどの多様データを取り込み、グラフDBと生成AIを組み合わせるアーキテクチャが示されています。OSLCは標準REST APIで横断接続を担い、Syndeiaのようなデジタルスレッド基盤は、異なるリポジトリのアーティファクトをノード、関係をエッジとして結ぶグラフとしてデジタルスレッドを扱います。SysML v2 APIはシステム側の構造と要求、AP242は機械設計側の形状・PMI・分析・要求・製造情報を支えます。
User and GovernanceReasoning and ExecutionKnowledge LayersIngestion and NormalizationAuthoritative SourcesSysML v2 / RequirementsPLM / BOM / Change / DocsCAD / PMI / AP242CAE / Simulation / TestERP / MES / QMS / FieldConnectors / APIs / MCP / ETLParser / OCR / Metadata EnrichmentCanonical IDs / Units / Revision / EffectivityAuthoritative Digital Thread GraphExtracted Graph and Community SummariesVector IndexKeyword and Exact IndexSkillBank and Agent SkillsModel and Simulation RegistryQuery Planner and Policy RouterHybrid Retrieval and Graph ExpansionAgentic WorkflowTool GatewayConstraint Check and Solver Re-run GateEngineer Copilot UICitations and Path TraceHuman Approval WorkflowAudit Log and MetricsControlled Write-back to PLM/ALMShow code
この構成で大事なのは、グラフを二種類に分けることです。ひとつは、PLM/MBSE/AP242/OSLCから来る“権威グラフ”で、版・承認・適用範囲・parent-child構造・PMI・解析リンクなど、監査対象になる関係を保持します。もうひとつは、GraphRAGやLLM抽出で得る“推論補助グラフ”で、議事録や設計根拠文書から暗黙関係を補います。回答生成では、まず権威グラフで正本関係を押さえ、足りない説明可能性だけ補助グラフから借りる順にしたほうが、安全です。
推奨エンティティ関係図
以下は、タービン設計向けに最低限持っておきたいエンティティ関係です。これは標準そのものではなく、SysML v2、AP242、OSLC、デジタルスレッド実装を踏まえた実務的な統合図です。
verified_byconstrainsallocated_todefined_byexchanged_asusesanalyzed_byproducesmanufactured_byaffected_byevidenced_byrevisesapprovescitesgrounded_byREQUIREMENTVERIFICATION_CASEFUNCTIONPARTCAD_MODELAP242_PACKAGEMATERIAL_SPECSIMULATION_CASESIMULATION_RESULTPROCESS_PLANISSUE_REPORTFIELD_EVENTCHANGE_ORDERDECISION_RECORDEVIDENCE_DOCShow code
例示オントロジー
下表は、RDF/OWLで持つときのクラス設計例です。RDF/OWLは異なるスキーマ間のデータ統合や暗黙知の明示化に向き、SHACLで構造検証を掛けられます。AP242やSysML v2の属性を、そのまま RDF/JSON-LD に写す必要はありませんが、識別子・版・状態・適用範囲・根拠リンクは必須です。
| クラス | 役割 | 主要属性 | 主要関係 | 代表ソース |
|---|---|---|---|---|
| Requirement | 要求・制約の正本 | id, text, safety_class, effectivity, verification_status | constrains Function, verified_by VerificationCase | ALM / SysML v2 |
| Function | 機能分解 | id, name, owner, criticality | allocated_to Part | MBSE |
| Part | 設計対象 | part_no, revision, lifecycle_state, family, serial_effectivity | defined_by CADModel, analyzed_by SimulationCase, revised_by ChangeOrder | PLM |
| CADModel | 形状定義 | file_id, format, checksum, authoring_tool | exchanged_as AP242Package | CAD / PLM |
| AP242Package | 中立交換表現 | edition, pmi_scope, geometry_scope, export_date | represents Part | AP242 |
| MaterialSpec | 材料仕様 | spec_id, material_code, temperature_limit | used_by Part | PLM / 材料DB |
| SimulationCase | 解析ケース | solver, model_revision, load_case, boundary_condition_hash | produces SimulationResult, grounded_by EvidenceDoc | CAE |
| SimulationResult | 解析結果 | metric_name, metric_value, margin, units | validates Requirement | CAE / Data Lake |
| ProcessPlan | 工程知識 | routing_id, plant, operation_seq | manufactured_by Part | ERP / MES |
| IssueReport | 不具合・逸脱 | issue_id, severity, discovered_date, status | affected_by Part, evidenced_by FieldEvent | QMS |
| ChangeOrder | 変更統制 | eco_id, reason_code, approval_state | revises Part | PLM |
| DecisionRecord | 判断理由 | decision_id, rationale, approver, review_meeting | cites EvidenceDoc, approves ChangeOrder | 文書庫 / レビューDB |
| EvidenceDoc | 根拠文書 | doc_id, title, source_uri, page_anchor, confidentiality | grounds SimulationCase, cited_by DecisionRecord | DMS / Share / Teamcenter |
メタデータ・スキーマのたたき台
製造業ナレッジAIで効くメタデータは、「検索に便利な属性」ではなく、「誤答を予防する属性」です。Teamcenter Copilotも、知識ベースの範囲制御、継続更新、引用、権限チェックを強く打ち出していて、実際に ETL、chunking、OCR、構造化データ索引を組み合わせています。したがって、revision・lifecycle_state・effectivity・approval_state・source_system・ACL・trace anchors を最初から schema に入れるべきです。
jsonCopy{
"artifact_id": "PART-TRB-BLADE-00123",
"artifact_type": "Part",
"title": "Stage1 Rotor Blade",
"part_number": "TRB-BLD-00123",
"revision": "C.4",
"lifecycle_state": "Released",
"approval_state": "Approved",
"effectivity": {
"product_family": "GTX",
"serial_from": "5000",
"serial_to": "9999"
},
"source_system": "PLM",
"source_uri": "plm://teamcenter/item/TRB-BLD-00123/C.4",
"confidentiality": "Internal",
"export_control": "NLR",
"language": "ja",
"units_system": "SI",
"linked_requirements": ["REQ-TEMP-019", "REQ-LIFE-042"],
"linked_simulation_cases": ["CFD-2026-044", "FEA-2026-118"],
"linked_change_orders": ["ECO-2026-209"],
"anchors": {
"cad_feature_ids": ["FACE_23", "EDGE_201"],
"pmi_ids": ["PMI-45", "PMI-46"],
"document_pages": [12, 18]
},
"acl_tags": ["program:GTX", "role:design", "site:JP-ENG"],
"hash": "sha256:...",
"embedding_version": "bge-m3-v2",
"ontology_version": "turbine-kg-0.9.0"
}
yamlCopyname: blade-temperature-margin-review
description: Review likely causes when blade thermal margin drops after a revision change
invocation_conditions:
- query mentions thermal margin, blade, revision, or coating
contraindications:
- no released revision is identified
workflow_steps:
- resolve exact part revision and effectivity
- retrieve linked requirements and thermal simulation cases
- compare changed materials, PMI, and boundary conditions
- retrieve related issue reports and test evidence
- summarize causal hypotheses with citations and confidence
constraints:
- only released and approved artifacts
- do not recommend geometry change without solver rerun
outputs:
- causal summary
- evidence path
- missing-data checklist
supporting_evidence:
- REQ-TEMP-019
- CFD-2026-044
- ECO-2026-209
confidence: 0.82
version: 1.1.0
owner: design-knowledge-office
実装パターンと評価設計
データ取り込みは、まず source-of-truth を切り分けるところから始めます。PLM/ALM/ERP/MES/QMS/CAE などの構造化系は API / ETL で正規化し、文書系は parser と OCR を通して evidence 化し、最後に canonical ID を付与して graph・vector・keyword・skill へ分配します。AWSの製造デジタルスレッド指針も、DMS / DataSync → S3 → Neptune → LLM オーケストレーションという流れを採っていて、Teamcenter Copilotも、ETL、Apache Tika、OCR、structured info indexing を前提にしています。設計上の核心は「取り込み」ではなく、「同一性解決」と「版・権限・適用範囲の正規化」です。
推奨インデキシング戦略
ベクトル検索と記号検索は、どちらかを選ぶものではなく、役割分担で考えるべきです。Elastic は hybrid search に RRF を推奨し、Qdrant は dense / sparse / multivector を RRF や DBSF で融合し、その上で recency や payload 条件を formula query で重ねられるとしています。製造設計では、この fusion の上に、グラフ展開と symbolic constraint をさらに重ねるのが実務的です。
| 段階 | 目的 | 推奨索引 | 主な問い合わせ |
|---|---|---|---|
| Exact Retrieval | 部番、要求ID、材質規格、ECO番号を正確に引く | keyword / inverted index / ID map | 「TRB-BLD-00123 C.4」 |
| Semantic Retrieval | 言い換えや自然文を拾う | dense vectors | 「翼先端温度余裕が減った理由」 |
| Sparse Retrieval | 専門語・略号・規格番号を拾う | BM25 / sparse vectors | 「TBC CMSX-4 PMl 45」 |
| Graph Expansion | 影響関係をたどる | property graph / RDF graph | 「この変更がつながる解析・不具合」 |
| Symbolic Filter | 版・承認・effectivity を絞る | metadata predicates / SHACL-like checks | 「Released only」「serial 5000以降」 |
| Skill Retrieval | 再利用可能手順を選ぶ | SkillBank / skill registry | 「温度余裕低下レビュー」 |
| Rerank and Pack | context window を詰める | cross-encoder / citation packer | 最終コンテキスト構成 |
このときの retrieval policy は、問い合わせタイプで変えるべきです。部番や要求IDが含まれる質問では exact first、設計理由や影響波及では graph first、作業依頼や診断依頼では skill first が安定します。Agentic RAG はこの方針転換を自動化するための外殻として使うのがよく、LangChain、LlamaIndex、Haystack、Difyはいずれも、エージェントや多段ワークフローの器として使えます。
CAEとSimulation-AIの収束点
CAE/Simulation-AI の現在地は、「ソルバー置換」ではなく「探索の前倒し」です。Ansys SimAI は既存シミュレーションから学習したAI予測で設計代替案を高速に評価する方向、GeomAI は過去設計から幾何アイデアを生成する方向、PhysicsAI は design variables なしでも CAE データから高速予測モデルを作る方向にあります。Altair系の公式ページでも、PhysicsAI は従来ソルバーを補完するもので、クリティカル設計は従来CAE/CFDソルバーで最大限の信頼性を確認すべきだと明示しています。NAFEMSの2026カンファレンス案内でも、engineering 向け AI では explainability、uncertainty quantification、confidence estimation、validation strategy が重要だとされています。
したがって、安全な検証パターンはかなり明確です。まず GeomAI / generative design で候補を広く作り、次に SimAI / PhysicsAI で高速にスクリーニングし、要求・公差・工程制約をルール層でふるい、高価値な候補だけを高忠実度ソルバーで再計算し、最後に試験・認証のゲートへ通します。AIサロゲートは exploration engine、ソルバーは evidence engine と役割を分けるべきで、後者を削るべきではありません。これは設計提案ですが、各ベンダー文書が示す適用範囲と、trustworthy engineering AI の要件から自然に導かれます。
評価メトリクスとテストケース
評価は、検索品質、回答品質、ワークフロー品質、運用品質に分ける必要があります。RAGPerf は embedding / indexing / retrieval / reranking / generation を分離し、throughput、CPU/GPU利用、memory footprint と並んで、context recall、query accuracy、factual consistency を測る枠組みを示しています。TruLens は retrieved context / tool calls / plans を含む agent trace を評価でき、RAG Triad は context relevance / groundedness / answer relevance を分けて測る考え方を提供します。Ragas は“vibe checks”から systematic evaluation loops へ移るための実験駆動評価を掲げています。
下表は、タービン設計知識系で最初に作るべき回帰テスト例です。内容は本稿の提案ですが、評価軸は上のRAGPerf / TruLens / Ragasに沿っています。
| テスト問い合わせ | 期待される主取得対象 | 最低評価軸 | 合格条件の例 |
|---|---|---|---|
| Rev C.4 以降で翼温度余裕が下がった理由は | Part revision, Requirement, MaterialSpec, SimulationCase, ChangeOrder, Test evidence | context recall, groundedness, citation coverage | 主要根拠ノードを 90% 以上取得し、回答に引用と改訂版明記 |
| この公差逸脱はどのPMIと工程に紐づくか | AP242 PMI, ProcessPlan, NCR, affected Part | exact match precision, path completeness | 誤部番ゼロ、工程とPMIの両方に到達 |
| この変更がどの解析ケースを無効化するか | ChangeOrder, SimulationCase, model revision, assumptions | graph path accuracy | 変更→解析ケース→前提条件の経路が出る |
| 翼先端クリアランス見直しのレビュー手順を出して | Skill contract, requirements, linked simulations | task success, plan quality | 手順列、必要根拠、未充足項目が出る |
| 量産機 serial 5000以降のみで起きる不具合か | effectivity, serial range, IssueReport, FieldEvent | symbolic filter correctness | effectivity 条件を誤らず、該当/非該当が説明可能 |
| 推奨対策案を三つ出して根拠を比較して | requirements, decision records, validated sims | answer relevance, factual consistency | 各案に別根拠と未確定点が添付される |
端から端までのシナリオ
最後に、実際のエンドツーエンド像を、タービン翼の例で示します。問い合わせは「Stage1 rotor blade の Rev C.4 で、熱余裕が落ちた根本要因を、変更履歴と解析条件込みで説明して」です。この問いは、文章検索だけでは不十分で、exact match、graph expansion、skill、solver gate が全部必要です。GraphRAGやSkillBankが“理解の補助線”を作り、PLM/AP242/CAEが“正本”を支え、最終的に引用付きで根拠経路を返す形になります。
| フェーズ | エージェントの動き | 出力 | ルートコーズのトレース |
|---|---|---|---|
| 入力解釈 | part number / revision / issue type を抽出し、skill 適用可否を判定 | query plan | Query → Part(C.4) → Skill(blade-temperature-margin-review) |
| 厳密検索 | PLM から Part revision, ChangeOrder, release state, effectivity を取得 | 正本候補セット | Part(C.4) → ECO-2026-209 |
| グラフ展開 | Requirement, linked simulations, material changes, related issues をたどる | 影響グラフ | ECO → MaterialSpec / SimulationCase / IssueReport |
| 文書・要約取得 | GraphRAG / RAPTOR で議事録・レビュー記録・試験報告の全体要点を取得 | 設計判断の背景 | DecisionRecord ↔ EvidenceDoc ↔ TestReport |
| 制約検証 | Released only, approved only, serial range check | フィルタ済み根拠 | revision/effectivity/approval の整合確認 |
| 因果仮説生成 | material change, boundary condition shift, cooling margin assumptions を比較 | 仮説ランキング | Requirement ↔ Simulation ↔ Change ↔ Field evidence |
| 安全弁 | high-risk 推奨だけ solver rerun required に振る | “要再計算”フラグ | AI hypothesis → Verify gate |
| 最終回答 | citations と evidence path 付きで提示 | 回答、未確定点、次アクション | Query → Part → ECO → Sim → Requirement → Issue |
このシナリオで重要なのは、AIが「根本原因を断定」することではなく、「どの根拠経路で、どの仮説がどこまで支持されるか」を返すことです。そこまでできれば、設計レビューは一気に速くなりますし、逆に evidence gap があれば、そのギャップ自体がレビュー価値になります。
ガバナンスと導入ロードマップ
ガバナンスの基本原則は、設計AIを“賢い検索UI”としてではなく、“権限を持った業務主体になりうるソフトウェア”として扱うことです。NISTの Generative AI Profile は、組織目標に沿った trustworthiness を設計・運用に組み込むためのプロファイルで、OWASPは prompt injection を最重要リスクとして挙げ、Agentic AI では tool misuse、data leakage など新しい失敗モードが出ると警告しています。MCP仕様も、ツールを任意コード実行として慎重に扱い、明示的同意を前提にしています。Teamcenter Copilot が permission checks と citations を前提にするのは、まさにこの方向です。
実装で必要な統制は、少なくとも次の七つです。第一に source ACL を chunk / node / edge / skill の全レイヤーへ継承すること。第二に revision、approval_state、effectivity を retrieval 前の hard filter にすること。第三に tool 実行は role-based allowlist と人間承認を通すこと。第四に cited answer を標準にし、未根拠回答率をKPIにすること。第五に スキルとプロンプトを Git で版管理し、変更差分をレビューできること。第六に trace log と telemetry を残すこと。第七に、AIサロゲートの採用判定と solver rerun 判定を分けることです。これは本稿の推奨ですが、標準・セキュリティ・PLMネイティブAIの知見から見ると、ほぼ必須です。
統制テーブル
| 統制対象 | 具体策 | 実装フック |
|---|---|---|
| 権限 | ACL を artifact / chunk / edge / skill に継承 | source_system ACL、attribute-based access control |
| 版管理 | revision / lifecycle / approval / effectivity を検索前フィルタ | metadata predicate、graph constraint |
| 根拠性 | citation 強制、回答ごとに evidence path を保持 | cited answer schema、path trace UI |
| ツール安全 | MCP tool allowlist、明示承認、sandbox | tool gateway、human approval node |
| プロンプト安全 | untrusted content 隔離、tool-output sanitization | parser quarantine、prompt firewall |
| 変更監査 | query / retrieved set / model version / tool calls を保存 | OpenTelemetry / audit store |
| モデル安全 | surrogate は候補選別、最終判断は solver/test | verify gate、risk class rule |
フェーズ型ロードマップ
以下は、予算未指定を前提にした現実的な段階導入案です。金額は置かず、人員の目安だけを示します。数値は本稿の提案ですが、必要機能の広さは上記の標準とツール群に基づきます。
| フェーズ | 期間目安 | 主成果物 | 目安体制 | 主KPI |
|---|---|---|---|---|
| 基盤定義 | 4〜6週 | canonical ID、メタデータ、オントロジー、権限設計 | 3〜5名 | 主要データ源の識別子統一率、アクセス制御整備率 |
| ベース検索 | 6〜10週 | hybrid retrieval、引用付きQA、exact lookup | 4〜6名 | context recall、citation coverage、未根拠回答率 |
| デジタルスレッド | 8〜12週 | graph layer、OSLC / API links、変更波及クエリ | 5〜8名 | path completeness、change impact query 成功率 |
| スキル化 | 8〜12週 | SkillBank、レビュー/診断スキル、承認ゲート | 5〜7名 | task success、human override rate、plan quality |
| CAE統合 | 10〜16週 | simulation registry、surrogate screening、solver gate | 5〜8名 + CAE担当 | candidate-to-solver conversion、再利用率、検証通過率 |
| エンタープライズ化 | 継続 | observability、audit、baseline compare、write-back | 4〜6名 + 運用 | ROIまでの期間、設計レビュー時間、インシデント率 |
成功指標の置き方
技術KPIは retrieval と grounding を中心に置くべきですが、事業KPIは「設計レビューが何時間短くなったか」「再利用できた解析ケースがどれだけ増えたか」「変更影響調査の漏れがどれだけ減ったか」で見るべきです。GleanのようなWork AIベンダーは adoption や ROI を前面に出していますが、設計領域ではそれをそのまま使うのではなく、trace quality と engineering throughput に翻訳する必要があります。
ベンダーとツールの比較
以下は、PoC と enterprise 導入の両方を見据えた比較表です。できるだけ公式資料・一次情報を優先しました。評価は、このレポートの用途に照らした分析です。
| ツール | 区分 | 主機能 | 強み | 注意点 | PoC適性 | Enterprise適性 | 主な根拠 |
|---|---|---|---|---|---|---|---|
| Microsoft GraphRAG | OSS / retrieval | 知識グラフ、コミュニティ要約、global/local/DRIFT search | 多段関係・全体俯瞰に強い | 抽出グラフの品質管理と prompt tuning が必要 | 高い | 高い | |
| LangChain | agent framework | エージェント実行環境、ツール呼び出し、観測 | 柔軟性が高い | 設計知識そのものは別途必要 | 高い | 中〜高 | |
| LlamaIndex | data / workflow | data-centric agent、workflow、document intelligence | 文書中心のAI開発に強い | 工学的権威データは別設計が必要 | 高い | 高い | |
| Haystack | pipeline framework | RAG、self-correction loops、agents、multimodal search | 生成・検索パイプラインを分解しやすい | 実装主導になりやすい | 高い | 高い | |
| Dify | low-code platform | agentic workflow、RAG、MCP integration/publish | 立ち上がりが速い | 深い工学セマンティクスは自作が必要 | 非常に高い | 中〜高 | |
| Onyx | open-source enterprise AI | RAG、deep research、50+ connectors、MCP | セルフホストしやすい | 工学固有オントロジーは別途必要 | 高い | 中〜高 | |
| Glean | enterprise work AI | agents、assistant、search、connectors、governance | 社内知識横断は強い | PLM/CAE固有モデルまで入れるには拡張が要る | 中 | 高い | |
| Teamcenter Copilot | PLM-native AI | knowledge bases、BOM exploration、document intelligence、citations | PLM正本と権限制御に近い | Teamcenter中心の世界観 | 中 | 非常に高い | |
| Dassault Virtual Companions / CATIA AI | PLM/CAD-native AI | virtual companions、generative experiences | 3DEXPERIENCE / virtual twin 文脈に強い | プラットフォーム依存が強い | 中 | 高い | |
| Ansys SimAI / GeomAI | simulation AI | 高速予測、形状探索、生成設計補助 | 解析前倒しに強い | 最終認定はソルバー/試験が必要 | 中 | 高い | |
| PhysicsAI | simulation AI | CAEデータから高速予測、design variables 不要でも可 | 既存CAE再利用に強い | 正式判断の置換ではない | 中 | 高い | |
| Syndeia | digital thread platform | SysML/PLM/ALM/CAE 横断連携、graph queries、baselines | 異種ツール横断の traceability が強い | 統合作業が前提 | 中 | 非常に高い |
最後に、タービン設計システムに対する私の結論を一文で言うと、**勝つ構成は「RAGを高度化すること」ではなく、「設計知識を権威グラフ、証拠文書、再利用スキル、物理検証の層に分けて、必要に応じてLLMが横断すること」**です。GraphRAG、Agentic RAG、SkillBank、MCP、SysML v2、AP242、OSLC、Simulation-AI は、別々の流行語ではなく、同じ設計基盤の別レイヤーだと理解すると、何をどの順番で導入すべきかがかなりクリアになります。

コメント